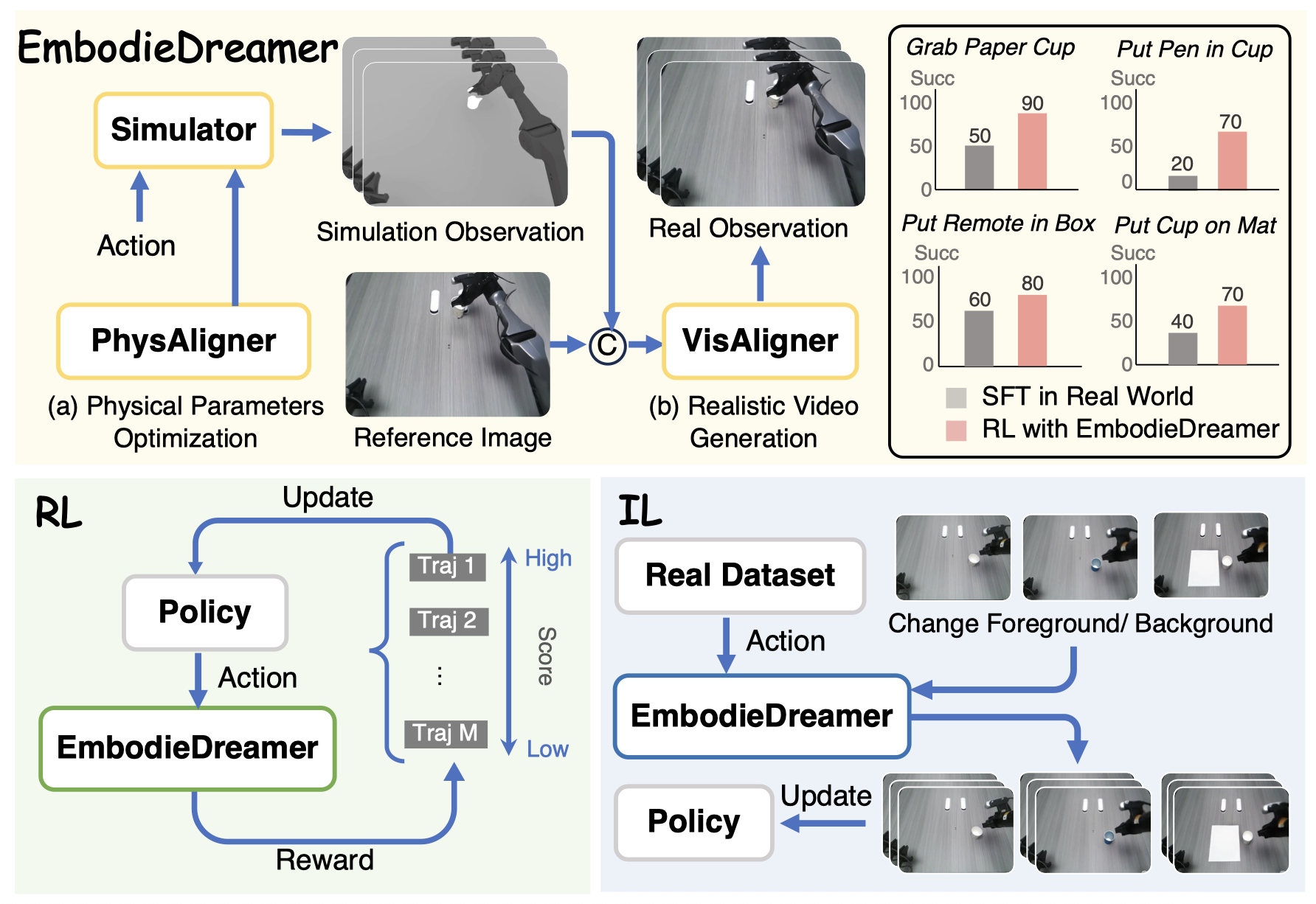
The rapid advancement of Embodied AI has led to an increasing demand for large-scale, high-quality real-world data. However, collecting such embodied data remains costly and inefficient. As a result, simulation environments have become a crucial surrogate for training robot policies. Yet, the significant Real2Sim2Real gap remains a critical bottleneck, particularly in terms of physical dynamics and visual appearance. To address this challenge, we propose EmbodieDreamer, a novel framework that reduces the Real2Sim2Real gap from both the physics and appearance perspectives. Specifically, we propose PhysAligner, a differentiable physics module designed to reduce the Real2Sim physical gap. It jointly optimizes robot-specific parameters such as control gains and friction coefficients to better align simulated dynamics with real-world observations. In addition, we introduce VisAligner, which incorporates a conditional video diffusion model to bridge the Sim2Real appearance gap by translating low-fidelity simulated renderings into photorealistic videos conditioned on simulation states, enabling high-fidelity visual transfer. Extensive experiments validate the effectiveness of EmbodieDreamer. The proposed PhysAligner reduces physical parameter estimation error by 3.74% compared to simulated annealing methods while improving optimization speed by 89.91%. Moreover, training robot policies in the generated photorealistic environment leads to a 29.17% improvement in the average task success rate across real-world tasks after reinforcement learning. Code, model and data will be publicly available.
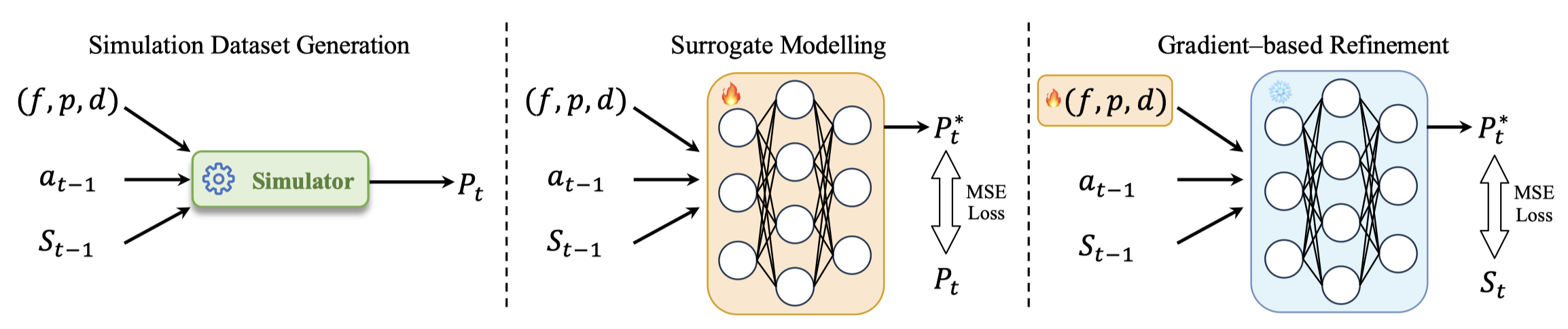
The figure illustrates the workflow of PhysAligner. First, a large amount of data is generated using a simulator. Then, a surrogate model is trained to fit the data. Finally, the physical parameters are optimized through gradient descent.
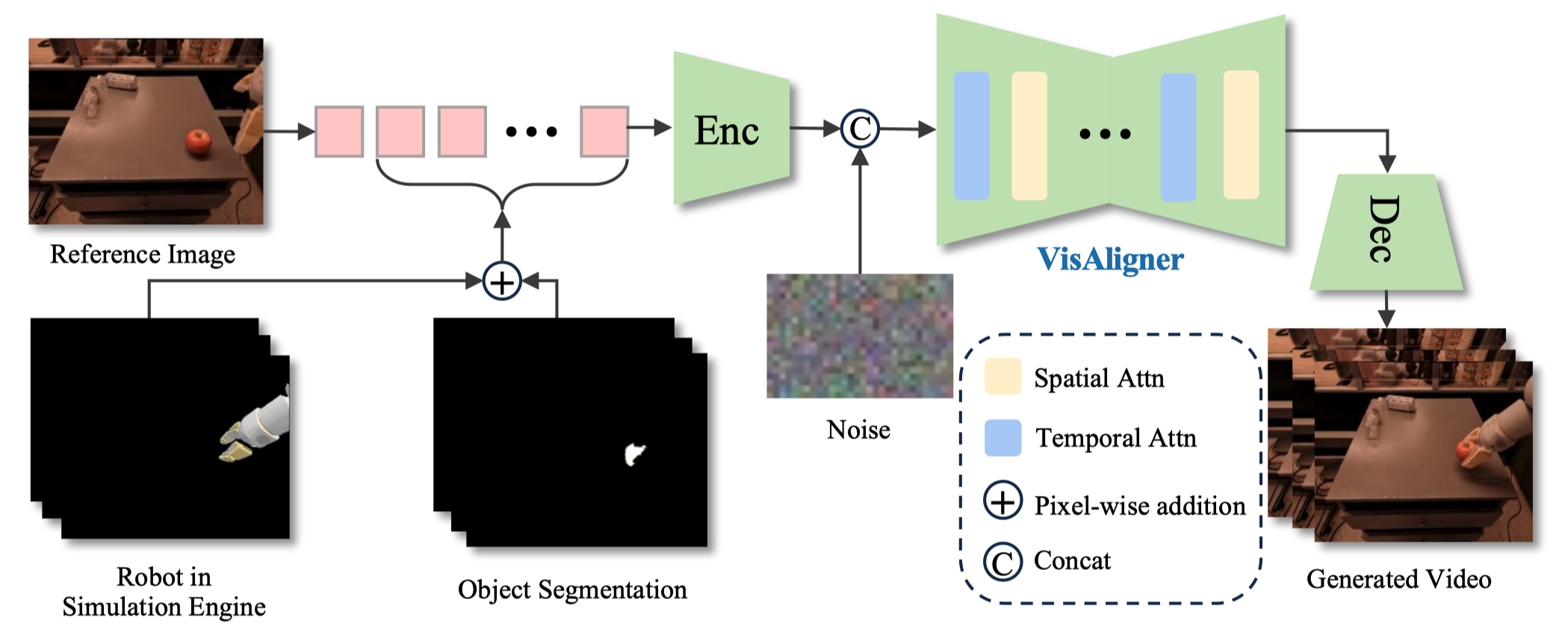
The framework of VisAligner. A reference image containing the initial background and robot appearance information serves as the first frame of the conditioned video. The subsequent frames are generated by performing pixel-wise addition of the robot's motion observations from the simulated environment and the segmentation masks of the foreground objects. These frames are then encoded into latents via a VAE encoder, concatenated with noise along the channel dimension, and input to VisAligner for denoising. Spatial-temporal attention mechanisms are employed to capture long-range dependencies across both spatial and temporal dimensions, thereby enhancing the coherence and visual quality of the generated video. The final video is obtained by decoding the denoised latents.
In each video: Left - GT video (Real world), Middle - Simulation video, Right - Generation video (Our EmbodieDreamer)
Reinforcement learning process with EmbodieDreamer. Policy receives one-view visual input to produce actions, which are executed in the simulator to generate raw observations. These observations are then processed by VisAligner to render photorealistic videos. The last frame of the rendered video serves as the reference image for the next iteration of policy execution. This closed-loop process iterates for a fixed number of steps, yielding trajectories of consistent length with photorealistic visual observations.
@article{wang2025embodiedreamer,
title={EmbodieDreamer: Advancing Real2Sim2Real Transfer for Policy Training via Embodied World Modeling},
author={Boyuan Wang and Xinpan Meng and Xiaofeng Wang and Zheng Zhu and Angen Ye and Yang Wang and Zhiqin Yang and Chaojun Ni and Guan Huang and Xingang Wang},
journal={arXiv preprint arXiv:2507.05198},
year={2025},
}